Scale-out has the ability to change everything
In the software-only space solutions like Datacore and Nexenta are really quite good (I have used and deployed both) and I still recommend them for customers that need some of their unique features, but they share a fundamental limitation in that they are based on a traditional scale-up architecture model. The result is that there is still a fair bit of manual housekeeping involved in maintaining, migrating and growing the overall environment. Adding and removing underlying storage remains a relatively manual task and the front end head units remain potential choke points. This is becoming more and more of an issue with the arrival of high performance flash, especially when installed directly on the PCIe bus. The hiccup is that you can end up in situations where a single PCIe Flash card can generate enough IO to saturate a 10GbE uplink and a physical processor which means you need bigger and bigger head units with more and more processing power.
So the ideal solution is to match the network, processor and storage requirements in individual units that spread the load around instead of all transiting through central potential choke points. We’re seeing a number of true scale-out solutions hitting the market right now that have eliminated many of the technical issues that plagued earlier attempts at scale-out storage.
The secondary issue with scale out changes the way you purchase storage over time. The over time part is a key factor that keeps getting missed in most analysis of ROI and TCO since most enterprises that are evaluating new storage systems are doing so in the context of their current purchasing and implementation methodology: They have an aging system that needs replacing so they are evaluating the solution as a full on replacement without truly understanding the long term implications of a modern scale-out system.
So why is this approach different? There are two key factors that come into play:
- You buy incremental bricks of capacity and performance as you need them
- Failure and retirement of bricks are perceived identically by the software
To the first point, technological progress makes it clear that if you can put off a purchase you will get a better price/capacity and price/performance ratio that you have today. Traditionally many storage systems are purchased with enough head room for the next 3 years which means you’re buying tomorrow’s storage at today’s prices.
So this gives us the following purchase model:
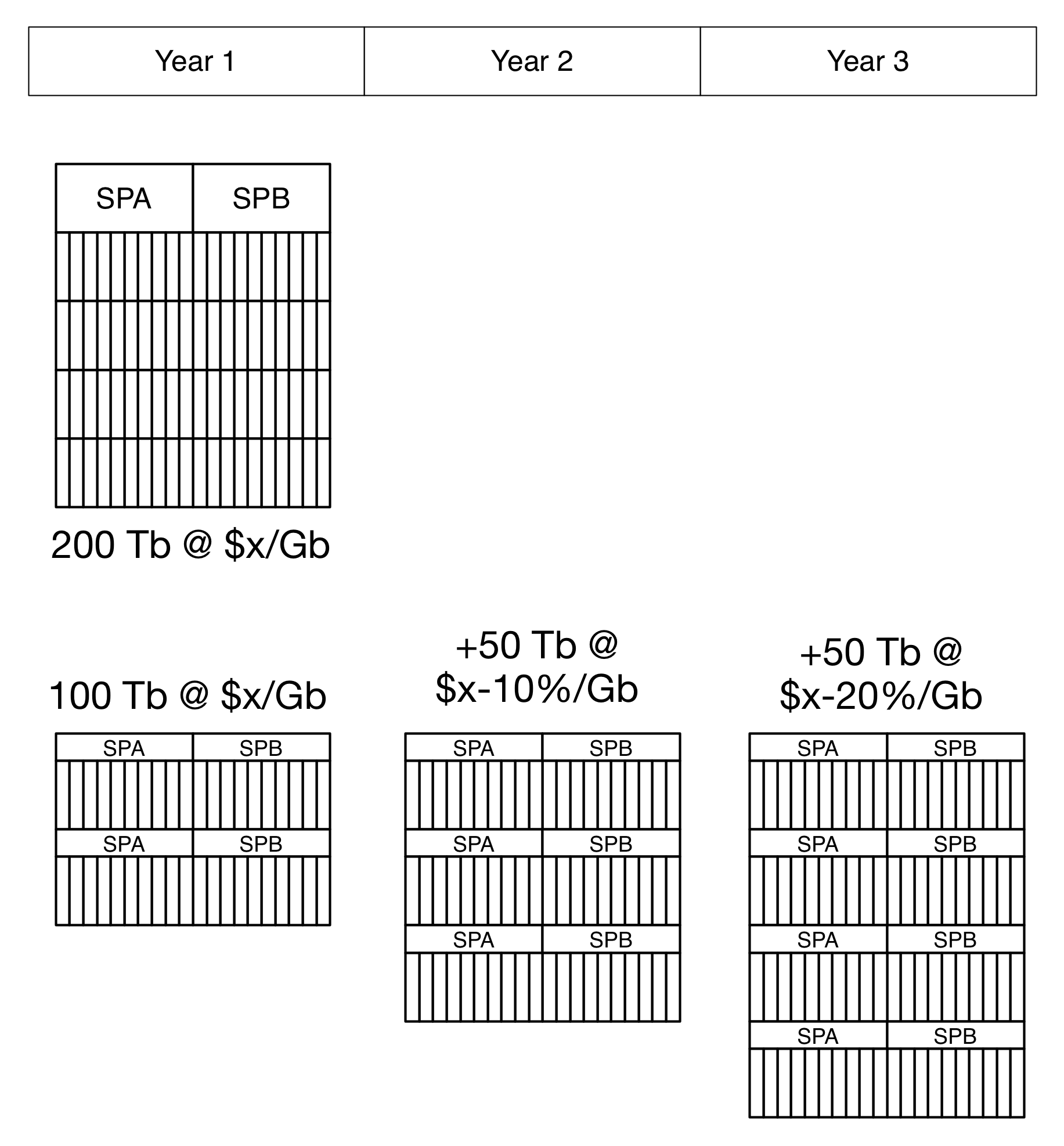
This is a simplified model based on the cost/Gb of storage but applies to all axes involved in storage purchase decisions such as IOPS, rack density, power consumption, storage network connections and so on. Also remembering that you might end up with bricks that still cost $x, but have 50% more capacity in the same space. A key feature of properly done scale out storage is the possibility of heterogeneous bricks where the software handles optimal placement and distribution for you automatically. For “cold” storage, we’re seeing 3Tb drives down under the $100 mark, but 6 Tb drives are now available to the general public. If you filled up your rack with 3Tb drives today, you’d need twice the space and consume twice the power than if you could put off the purchase until the 6Tb drives come down in price. For SSDs, Moore’s Law is working just fine as we see die-shrinks increase the storage density and performance on a regular cycle.
In some organisations this can be a problem since they have optimized their IT purchasing processes around big monolithic capital investments like going to RFP for all capital investments which means that the internal overhead incurred can be counterproductive. But these are often the same organisations that are pushing for outsourcing everything to cloud services so that storage becomes OpEx, but this type of infrastructure investment lives somewhere between the two and needs to be treated as such. Moving straight to the cloud can be a lot more expensive, even when internal soft costs are factored in. Don’t forget that your cloud provider is using the the exact same disks and SSDs as you are and needs to charge for their internal management plus a margin.
And on to the upgrade cycle…
The other critical component of scale-out shared-nothing storage is that failure and retirement are perceived as identical situations from a data availability perspective (although they are different from a management perspective). Properly designed scale-out systems like Coho Data, ScaleIO, VSAN, Nutanix, SimpliVity and others guarantee availability of data by balancing and distributing copies of blocks across failure domains. At the simplest level a policy is applied that each block or object must have at least two copies in two separate failure domains, which for general purposes means a brick or a node. You can also be paranoid with some solutions and specify more than two copies.
But back to the retirement issue. Monolithic storage systems basically have to be replaced at least every 5 years since otherwise your support costs will skyrocket. Understandably so since the vendor has to keep warehouses full of obsolete equipment to replace your aging components. And you’ll be faced with all the work of migrating your data onto a new storage system. Granted, things like Storage vMotion make this considerably less painful that it used to be, but it’s still a big task and other issues tend to crop up, like do you have space in your datacenter for two huge storage systems during the migration? Enough power? Are the floors built to take the weight? Enough ports on the storage network?
The key here is that in case of a brick failure in a scale-out system, this is detected and treated as a violation of the redundancy policy. So all of the remaining bricks will redistribute/rebalance copies of the data to ensure that the 2 or 3 copy policy is respected without any administrative intervention. When a brick hits the end of its maintainable life, it just gets flagged for retirement, unplugged, unracked and recycled and the overall storage service just keeps running. This a nice two-for-one benefit that comes natively as a function of the architecture.
To further simplify things you are dealing with reasonably-sized server shaped bricks that fit into standard server racks, not monolithic full-rack assemblies.
Illustrated, this gives us this:
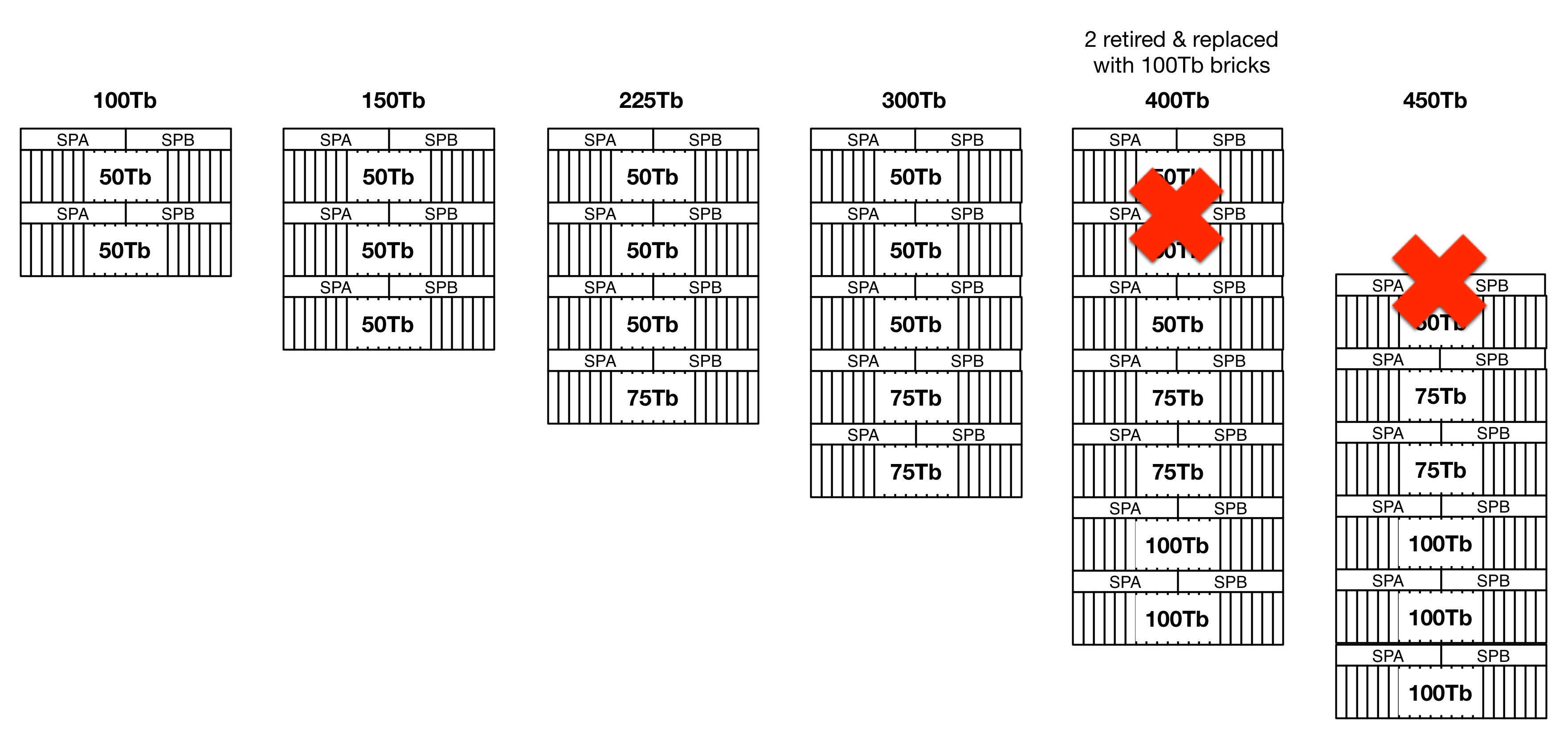
Again, this is a rather simplistic model, but with constantly growing storage density and performance, you are enabling the storage to scale with the business requirements. If there’s an unexpected new demand, a couple more bricks can be injected into the process. If the demand is static, then you’re only worried about the bricks coming out of maintenance. It starts looking at lot more like OpEx than CapEx.
This approach also ensure that the bricks you are buying use components that are sized together correctly. If you are buying faster and more space on high performance PCIe SSD, you want to ensure that you are buying them with the current processors capable of handling the load and that you can handle the transition from GbE to 10GbE to 40GbE, …
So back to the software question again. Right now, I think that Coho Data and ScaleIO are two of the best standalone scale-out storage products out there (more on hyperconvergence later), but they are both coming at this from different business models. ScaleIO is strangely the software-only solution from the hardware giant, while Coho Data is the software bundled with hardware solution from part of the team that built the Xen hypervisor. Andy Warfield, Coho Data’s CTO has stated in many interviews that the original plan was to sell the software, but that they had a really hard time selling this into the enterprise storage teams that want a packaged solution.
I love the elegance of the zero configuration Coho Data approach, but wish that I wasn’t buying the software all over again when I replace a unit when it hits EOL. This could be regulated with some kind of trade-in program.
On the other hand, I also love the tunability and BYOHW aspects of ScaleIO, but find it missing the plug and play simplicity and the efficient auto-tiering of Coho Data. But that will come with product maturity.
It’s time to start thinking differently about storage and reexamining the fundamental questions and how we buy and manage storage.